(c) 2017 by Barton Paul Levenson
Nothing ruins a statistical analysis like picking a bad sample. Samples should be relevant to what you're investigating, and that means you have to avoid two big errors:
Inadequate sample size is usually fairly easy to overcome: get as many points as possible. Of course, reality often interferes with that goal. The more points you need, the more effort you have to make to collect them. In general, for 95% confidence in your results, one rule of thumb for linear regressions is:
100 points are adequate 200 points are good 400+ points are great
Of course, if you're dealing with the fifty states, you're not going to get 100 points. You work with what you can get.
Overcoming sample bias is harder. A famous poll showed the problem for all to see. In 1936, a magazine called the Literary Digest conducted a poll of no fewer than ten million voters--clearly they had adequate sample size. They predicted Republican Candidate Alf Landon would win the presidential election in a landslide, with 57% of the popular vote and 370 electoral votes.
In reality, Democrat Franklin Roosevelt got 61% of the vote and 523 electoral votes, to 37% and 8 electors for Landon.
The Digest had asked their own subscribers to answer their poll. Their subscribers were much more likely than the general public to have higher incomes and Republican sympathies. So despite very much covering the adequate-sample-size issue, they failed miserably on the biased-sample issue.
There are many ways to overcome bias, though you can never eliminate it entirely. Use random methods, or as random as you can get. You can try the following methods:
| Method | Potential problems |
|---|---|
| Call random phone numbers | You miss people without phones, or who can't answer their phone when you're calling (are you calling during work hours?). |
| Mail random surveys | You miss people without permanent addresses, people on vacation who forgot to forward their mail, and people who can't read or write. |
Anyway, you see the problem. All you can do is your best. Be clear about what you were trying to investigate and how you gathered your sample. Cite your sources. And analyze. That's all you can do.
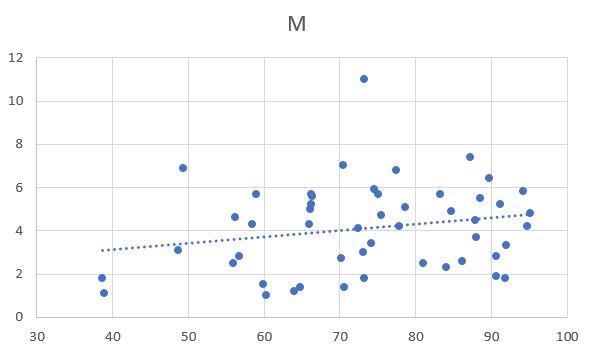
Anyway, considering the problem of sample size, let's do that regression of murder rates on urbanization using all fifty states (N = 50). That gives us:
| M = f(U) | N = 50 |
| R2 = 0.04320 | R̄2 = 0.02327 |
| F1,48 = 2.167 (p < 0.1475) | SEE = 2.010 |
| Name | β | t | p |
|---|---|---|---|
| M | 1.982 | 1.341 | 0.1862 |
| U | 0.02900 | 1.472 | 0.1475 |
Note that for a regression with one independent variable, the p value on the F statistic is the same as that for the t statistic on the independent variable. If you have more than one X, this no longer holds.
Clearly, this is still not a good regression, in the sense that it does nothing to confirm our thesis. It's hard to argue that our sample is biased, since we're using all fifty states. Perhaps states and provinces in comparable countries could be added to the sample? Why or why not?
Or maybe urbanization has nothing to do with the overall murder rate in a state! That's possible, too.
| Page created: | 04/12/2017 |
| Last modified: | 04/13/2017 |
| Author: | BPL |